Elasticsearch Toàn Tập: Search Engine Hiện Đại Cho Ứng Dụng Web
Trong thế giới số hóa hiện đại, việc tìm kiếm thông tin nhanh chóng và chính xác đã trở thành một yêu cầu thiết yếu. Từ những trang web thương mại điện tử với hàng triệu sản phẩm, đến các ứng dụng phân tích log phức tạp, khả năng tìm kiếm hiệu quả quyết định đến trải nghiệm người dùng và thành công của hệ thống. Elasticsearch - một trong những search engine mạnh mẽ nhất hiện nay, đã trở thành lựa chọn hàng đầu cho các doanh nghiệp và lập trình viên trên toàn thế giới.
Bài viết này sẽ đưa bạn vào hành trình khám phá toàn diện về Elasticsearch, từ những khái niệm cơ bản về search engine, kiến trúc phân tán, so sánh với các công nghệ khác, cho đến hướng dẫn triển khai thực tế trong các dự án hiện đại.
1. Search Engine là gì? Tại sao cần Search Engine trong ứng dụng hiện đại?
1.1. Search Engine (Công cụ tìm kiếm) là gì?
Search Engine có thể được hiểu như một hệ thống chuyên dụng được thiết kế để tìm kiếm, lọc và trả về thông tin từ một tập dữ liệu lớn một cách nhanh chóng và chính xác. Khác với cách tìm kiếm truyền thống bằng cách duyệt tuần tự qua dữ liệu (như sử dụng LIKE %keyword% trong SQL), search engine sử dụng các cấu trúc dữ liệu và thuật toán tối ưu để đạt được hiệu suất tìm kiếm vượt trội.
Search Engine hoạt động dựa trên nguyên lý lập chỉ mục (indexing). Thay vì tìm kiếm trực tiếp trên dữ liệu gốc, search engine xây dựng các cấu trúc chỉ mục đặc biệt (như Inverted Index) để có thể truy xuất thông tin trong thời gian gần như tức thì.
1.2. Tại sao ứng dụng hiện đại cần Search Engine?
Trong kỷ nguyên Dữ liệu lớn (Big Data), các ứng dụng hiện đại đối mặt với những thách thức về tìm kiếm mà cơ sở dữ liệu truyền thống không thể giải quyết hiệu quả:
Khối lượng dữ liệu khổng lồ: Các ứng dụng thương mại điện tử có thể có hàng triệu sản phẩm, các hệ thống log có thể tạo ra hàng terabyte dữ liệu mỗi ngày. Việc tìm kiếm trên khối lượng dữ liệu này bằng SQL truyền thống sẽ cực kỳ chậm.
Yêu cầu tìm kiếm phức tạp: Người dùng mong muốn có thể tìm kiếm không chỉ bằng từ khóa chính xác mà còn bằng từ đồng nghĩa, từ viết sai chính tả, hay thậm chí tìm kiếm theo ngữ cảnh và ý nghĩa.
Tốc độ phản hồi thời gian thực: Người dùng kỳ vọng kết quả tìm kiếm xuất hiện trong vài mili giây, không phải vài giây. Tốc độ này quyết định trực tiếp đến trải nghiệm người dùng.
Khả năng phân tích và tổng hợp: Ngoài tìm kiếm, ứng dụng cũng cần phân tích dữ liệu, tạo báo cáo, thống kê theo thời gian thực.
1.3. Các loại công cụ tìm kiếm phổ biến
Công cụ tìm kiếm toàn văn (Full-text Search Engine): Chuyên về tìm kiếm văn bản, hỗ trợ tìm kiếm theo ngữ nghĩa, từ đồng nghĩa. Ví dụ: Elasticsearch, Solr, Sphinx.
Công cụ tìm kiếm chuyên biệt (Specialized Search Engine): Chuyên biệt cho từng lĩnh vực như tìm kiếm hình ảnh (Computer Vision), tìm kiếm vector (Vector Database), tìm kiếm địa lý (GIS).
Hybrid Search Engine: Kết hợp nhiều phương pháp tìm kiếm khác nhau như full-text, vector search, faceted search.
1.4. Lợi ích khi sử dụng Search Engine chuyên dụng
Hiệu suất vượt trội: Tốc độ tìm kiếm nhanh hơn hàng trăm lần so với SQL LIKE queries trên cùng khối lượng dữ liệu.
Tính năng tìm kiếm nâng cao: Hỗ trợ tìm kiếm mờ (fuzzy search), tự động hoàn thành (autocomplete), làm nổi bật (highlight), xếp hạng theo độ liên quan.
Khả năng mở rộng: Có thể xử lý petabyte dữ liệu thông qua kiến trúc phân tán.
Phân tích thời gian thực: Không chỉ tìm kiếm mà còn có thể thực hiện aggregation, analytics phức tạp.
1.5. Nhược điểm và thách thức
Độ phức tạp: Đòi hỏi kiến thức chuyên môn về search engine, không đơn giản như SQL.
Tài nguyên hệ thống: Cần nhiều RAM và CPU hơn so với cơ sở dữ liệu truyền thống.
Đồng bộ dữ liệu: Cần giải quyết vấn đề đồng bộ giữa database chính và search index.
Chi phí vận hành: Thêm một thành phần vào hệ thống, đòi hỏi monitoring, backup, maintenance riêng.
2. Elasticsearch là gì? Vì sao lại mạnh mẽ đến vậy?
Elasticsearch là một công cụ tìm kiếm phân tán (distributed search engine), mã nguồn mở, được xây dựng trên nền tảng Apache Lucene. Nó được thiết kế để hoạt động với tốc độ cao, khả năng mở rộng linh hoạt và độ chính xác cao trong việc tìm kiếm và phân tích dữ liệu.
2.1. Đặc điểm nổi bật của Elasticsearch
RESTful API: Mọi tương tác với Elasticsearch đều thông qua HTTP REST API với định dạng JSON, giúp dễ dàng tích hợp với bất kỳ ngôn ngữ lập trình nào.
Thiết kế phân tán từ đầu: Elasticsearch được thiết kế từ đầu để hoạt động phân tán, có thể mở rộng từ 1 node đến hàng trăm node một cách dễ dàng.
Tìm kiếm gần thời gian thực: Dữ liệu được lập chỉ mục (index) và có thể tìm kiếm trong vòng vài giây, phù hợp cho các ứng dụng yêu cầu thời gian thực.
Không cần định nghĩa cấu trúc trước: Có thể lập chỉ mục dữ liệu mà không cần định nghĩa schema trước, tự động nhận diện kiểu dữ liệu.
Hỗ trợ đa thuê bao: Hỗ trợ nhiều chỉ mục (index) với các cấu hình khác nhau trên cùng một cụm máy chủ (cluster).
2.2. Lịch sử phát triển của Elasticsearch
Elasticsearch được tạo ra bởi Shay Banon vào năm 2010, xuất phát từ nhu cầu xây dựng một công cụ tìm kiếm dễ sử dụng và có khả năng mở rộng cao. Từ một dự án cá nhân, Elasticsearch đã phát triển thành một trong những công cụ tìm kiếm phổ biến nhất thế giới.
2010: Phiên bản đầu tiên của Elasticsearch được phát hành. 2012: Công ty Elastic được thành lập. 2013: Kibana được phát triển để trực quan hóa dữ liệu từ Elasticsearch. 2015: Logstash được tích hợp, tạo thành ELK Stack (Elasticsearch, Logstash, Kibana). 2021: Thay đổi giấy phép từ Apache 2.0 sang Elastic License, tạo ra sự phân chia trong cộng đồng và sự ra đời của OpenSearch.
2.3. Elasticsearch trong hệ sinh thái Elastic Stack
Elasticsearch không hoạt động một mình mà là thành phần cốt lõi của Elastic Stack:
Elasticsearch: Công cụ tìm kiếm cốt lõi Kibana: Bảng điều khiển và công cụ trực quan hóa Logstash: Đường ống xử lý dữ liệu Beats: Công cụ thu thập dữ liệu nhẹ Elastic Agent: Tác nhân thống nhất để thu thập dữ liệu
2.4. Tại sao Elasticsearch lại mạnh mẽ?
Inverted Index: Sử dụng cấu trúc dữ liệu Inverted Index của Lucene, cho phép tìm kiếm cực nhanh.
Phân tán thông minh: Tự động phân chia dữ liệu thành các shard và tạo bản sao để đảm bảo tính sẵn sàng cao.
Tổng hợp mạnh mẽ: Khả năng phân tích và tổng hợp dữ liệu thời gian thực mạnh mẽ hơn nhiều so với SQL.
Tùy chỉnh điểm số: Có thể tùy chỉnh thuật toán tính điểm độ liên quan để phù hợp với logic nghiệp vụ.
Hệ sinh thái plugin: Hàng trăm plugin để mở rộng chức năng và tích hợp với các hệ thống khác.
3. Kiến trúc cốt lõi của Elasticsearch

Để hiểu cách Elasticsearch đạt được hiệu suất và khả năng mở rộng vượt trội, chúng ta cần nắm vững kiến trúc phân tán và các thành phần cốt lõi của nó.
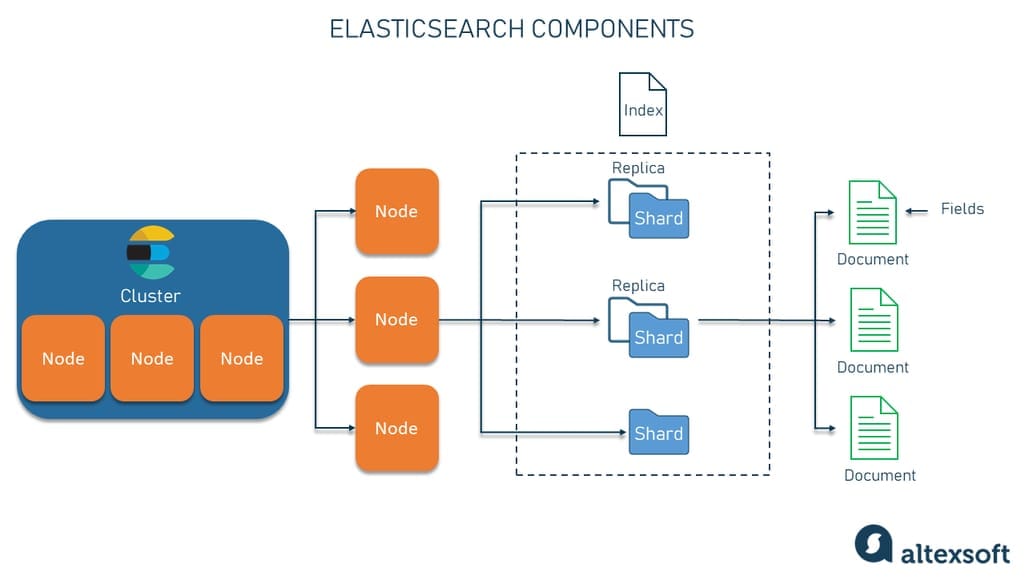
3.1. Mô hình phân tán: Cluster, Node, Shard
Cluster (Cụm máy chủ): Là tập hợp của một hoặc nhiều node (máy chủ) làm việc cùng nhau. Mỗi cluster có một tên duy nhất để phân biệt với các cluster khác.
Node (Máy chủ): Là một máy chủ đơn lẻ trong cluster, có thể đảm nhận nhiều vai trò khác nhau:
- Master Node: Quản lý siêu dữ liệu (metadata) của cluster, quyết định phân bổ shard
- Data Node: Lưu trữ dữ liệu và thực hiện các thao tác tìm kiếm
- Coordinating Node: Định tuyến yêu cầu và tổng hợp kết quả
- Ingest Node: Tiền xử lý dữ liệu trước khi lập chỉ mục
Shard (Phân đoạn): Là đơn vị nhỏ nhất của việc phân tán dữ liệu trong Elasticsearch:
- Primary Shard: Lưu trữ dữ liệu gốc, số lượng được định sẵn khi tạo chỉ mục
- Replica Shard: Bản sao của primary shard để đảm bảo tính sẵn sàng cao
3.2. Cấu trúc dữ liệu: Index, Document, Field
Index (Chỉ mục): Tương tự như cơ sở dữ liệu trong RDBMS, là nơi lưu trữ các tài liệu có cùng loại.
Document (Tài liệu): Đơn vị dữ liệu cơ bản, được biểu diễn dưới dạng JSON. Mỗi document có:
_index: Chỉ mục chứa tài liệu_id: Mã định danh duy nhất_source: Dữ liệu JSON gốc_score: Điểm độ liên quan khi tìm kiếm
Field (Trường): Các trường dữ liệu trong document, có thể có nhiều kiểu dữ liệu khác nhau:
text: Để tìm kiếm toàn vănkeyword: Để khớp chính xác, tổng hợpnumeric: integer, long, float, doubledate: Dấu thời gian và khoảng ngày thángboolean: true/falsegeo_point: Tọa độ địa lýnested: Đối tượng phức tạp
3.3. Mapping và Analysis
Mapping (Ánh xạ): Định nghĩa cách dữ liệu được lưu trữ và lập chỉ mục. Có hai loại:
- Dynamic Mapping: Elasticsearch tự động nhận diện kiểu dữ liệu
- Explicit Mapping: Nhà phát triển định nghĩa rõ ràng cấu trúc dữ liệu
Analysis (Phân tích): Quá trình xử lý văn bản trước khi lập chỉ mục:
- Character Filters: Loại bỏ thẻ HTML, chuẩn hóa ký tự
- Tokenizer: Chia văn bản thành các từ
- Token Filters: Chuyển thành chữ thường, loại bỏ từ dừng, trích xuất gốc từ
3.4. Inverted Index: Bí mật tốc độ
Inverted Index là cấu trúc dữ liệu cốt lõi giúp Elasticsearch tìm kiếm cực nhanh:
Document 1: "Elasticsearch là search engine mạnh mẽ"
Document 2: "Search engine giúp tìm kiếm nhanh chóng"
Inverted Index:
elasticsearch -> [doc1]
search -> [doc1, doc2]
engine -> [doc1, doc2]
mạnh -> [doc1]
mẽ -> [doc1]
giúp -> [doc2]
tìm -> [doc2]
kiếm -> [doc2]
nhanh -> [doc2]
chóng -> [doc2]
Khi tìm kiếm "search engine", Elasticsearch:
- Lookup "search" → [doc1, doc2]
- Lookup "engine" → [doc1, doc2]
- Intersection → [doc1, doc2]
- Tính score và rank kết quả
4. So sánh Elasticsearch với các công nghệ khác
Để đưa ra quyết định đúng đắn trong việc lựa chọn công nghệ, việc hiểu rõ ưu nhược điểm của Elasticsearch so với các giải pháp khác là rất quan trọng.
4.1. Elasticsearch vs PostgreSQL Full-Text Search
| Tiêu chí | Elasticsearch | PostgreSQL FTS |
|---|---|---|
| Hiệu suất | Cực nhanh cho tập dữ liệu lớn | Tốt cho tập dữ liệu nhỏ-vừa |
| Khả năng mở rộng | Mở rộng theo chiều ngang dễ dàng | Chủ yếu mở rộng theo chiều dọc |
| Độ phức tạp cài đặt | Phức tạp, cần hệ thống riêng | Đơn giản, tính năng tích hợp sẵn |
| Tính linh hoạt truy vấn | Query DSL mạnh mẽ | SQL quen thuộc |
| Tính điểm độ liên quan | Thuật toán tinh vi | Cơ bản |
| Sử dụng bộ nhớ | Cao (cần nhiều RAM) | Vừa phải |
| Giao dịch ACID | Không hỗ trợ | Đầy đủ |
| Phù hợp với | Ứng dụng cần tìm kiếm nhiều | Nhu cầu tìm kiếm đơn giản |
Khi nào chọn PostgreSQL FTS:
- Dữ liệu dưới 10 triệu bản ghi
- Không muốn thêm hệ thống mới
- Cần giao dịch ACID
- Nhóm phát triển chỉ biết SQL
Khi nào chọn Elasticsearch:
- Dữ liệu trên 10 triệu bản ghi
- Cần tìm kiếm phức tạp (mờ, tự động hoàn thành)
- Cần phân tích và tổng hợp
- Hiệu suất là ưu tiên hàng đầu
4.2. Elasticsearch vs Solr
| Tiêu chí | Elasticsearch | Solr |
|---|---|---|
| Độ khó học | Dễ học | Khó học hơn |
| Hỗ trợ JSON | JSON nguyên bản | Dựa trên XML (có hỗ trợ JSON) |
| Cộng đồng | Lớn và tích cực | Ổn định nhưng ít hơn |
| Phân tích dữ liệu | Tổng hợp mạnh mẽ | Phân loại truyền thống |
| Quản trị | Quản lý cluster đơn giản | Phức tạp hơn (SolrCloud) |
| Tính năng doanh nghiệp | Thương mại hóa (X-Pack) | Mã nguồn mở |
4.3. Elasticsearch vs MongoDB với tìm kiếm văn bản
| Tiêu chí | Elasticsearch | MongoDB |
|---|---|---|
| Mục đích chính | Công cụ tìm kiếm | Cơ sở dữ liệu tài liệu |
| Chất lượng tìm kiếm văn bản | Xuất sắc | Cơ bản |
| Thao tác CRUD | Hạn chế | Hỗ trợ đầy đủ |
| Tính nhất quán | Nhất quán cuối cùng | Có thể cấu hình |
| Giao dịch | Không có | ACID đầy đủ |
| Phân tích thời gian thực | Xuất sắc | Hạn chế |
4.4. Elasticsearch vs Vector Databases (Pinecone, Weaviate)
| Tiêu chí | Elasticsearch | Cơ sở dữ liệu Vector chuyên biệt |
|---|---|---|
| Tìm kiếm Vector | Hỗ trợ (kNN) | Được tối ưu hóa |
| Tìm kiếm truyền thống | Xuất sắc | Hạn chế |
| Tìm kiếm kết hợp | Tốt | Khác nhau |
| Hệ sinh thái | Trưởng thành | Đang phát triển |
| Độ phức tạp cài đặt | Trung bình | Thấp (được quản lý) |
| Chi phí | Tự quản lý hoặc cloud | Thường chỉ cloud |
5. Ứng dụng thực tế của Elasticsearch
Elasticsearch được sử dụng rộng rãi trong nhiều lĩnh vực khác nhau. Dưới đây là các trường hợp sử dụng phổ biến với ví dụ cụ thể.
5.1. Tìm kiếm và phân tích thương mại điện tử
Tìm kiếm sản phẩm thông minh:
{
"query": {
"multi_match": {
"query": "iphone 15 pro max",
"fields": ["title^2", "description", "brand", "category"],
"fuzziness": "AUTO"
}
},
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{"to": 10000000},
{"from": 10000000, "to": 20000000},
{"from": 20000000}
]
}
},
"brands": {
"terms": {"field": "brand.keyword", "size": 10}
}
}
}
Các trường hợp sử dụng cụ thể:
- Tự động hoàn thành: Gợi ý sản phẩm khi người dùng nhập
- Tìm kiếm phân loại: Lọc theo thương hiệu, giá, đánh giá
- Tìm kiếm cá nhân hóa: Xếp hạng dựa trên hành vi người dùng
- Phân tích: Theo dõi xu hướng tìm kiếm, sản phẩm phổ biến
Ví dụ thực tế: Tiki, Shopee sử dụng Elasticsearch để xử lý hàng triệu truy vấn mỗi ngày
5.2. Phân tích log và giám sát (ELK Stack)
Phân tích log ứng dụng:
{
"query": {
"bool": {
"must": [
{"range": {"@timestamp": {"gte": "now-1h"}}},
{"match": {"level": "ERROR"}}
]
}
},
"aggs": {
"error_timeline": {
"date_histogram": {
"field": "@timestamp",
"interval": "5m"
}
},
"top_errors": {
"terms": {"field": "message.keyword", "size": 10}
}
}
}
Các trường hợp sử dụng:
- Log tập trung: Thu thập log từ nhiều dịch vụ
- Giám sát thời gian thực: Cảnh báo khi có lỗi
- Phân tích hiệu suất: Theo dõi thời gian phản hồi, thông lượng
- Giám sát bảo mật: Phát hiện hoạt động đáng ngờ
Ví dụ thực tế: Netflix sử dụng ELK Stack để giám sát hàng triệu yêu cầu mỗi giây
5.3. Quản lý nội dung và tìm kiếm
Tìm kiếm nội dung trang web:
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "machine learning",
"boost": 3
}
}
},
{
"match": {
"content": "machine learning"
}
}
]
}
},
"highlight": {
"fields": {
"title": {},
"content": {"fragment_size": 150}
}
}
}
Các trường hợp sử dụng:
- Tìm kiếm trang: Tìm kiếm bài viết, tài liệu
- Đề xuất nội dung: Đề xuất nội dung liên quan
- Tìm kiếm toàn văn: Tìm kiếm trong PDF, Word documents
5.4. Phân tích và Thông kê Kinh doanh
Bảng điều khiển thời gian thực:
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "order_date",
"calendar_interval": "day"
},
"aggs": {
"revenue": {"sum": {"field": "total_amount"}},
"order_count": {"value_count": {"field": "order_id"}}
}
},
"top_products": {
"terms": {"field": "product_name.keyword", "size": 10},
"aggs": {
"total_sales": {"sum": {"field": "quantity"}}
}
}
}
}
Các trường hợp sử dụng:
- Phân tích doanh thu: Theo dõi doanh thu, phân tích xu hướng
- Hành vi người dùng: Tỷ lệ click-through, funnel chuyển đổi
- Thông số vận hành: Hiệu suất hệ thống, thống kê sử dụng
5.5. Tìm kiếm địa lý
Tìm kiếm theo vị trí:
{
"query": {
"bool": {
"must": [
{"match": {"category": "restaurant"}},
{
"geo_distance": {
"distance": "5km",
"location": {
"lat": 21.0285,
"lon": 105.8542
}
}
}
]
}
},
"sort": [
{
"_geo_distance": {
"location": {"lat": 21.0285, "lon": 105.8542},
"order": "asc",
"unit": "km"
}
}
]
}
Các trường hợp sử dụng:
- Dịch vụ dựa trên vị trí: Tìm kiếm nhà hàng, ATM
- Tối ưu hóa vận chuyển: Lập kế hoạch đường đi, quản lý khu vực
- Ứng dụng GIS: Phân tích dữ liệu dựa trên bản đồ
5.6. Quản lý thông tin an toàn và sự kiện (SIEM)
Phát hiện anomaly:
{
"query": {
"bool": {
"must": [
{"range": {"timestamp": {"gte": "now-1h"}}},
{"terms": {"event_type": ["login_failure", "suspicious_activity"]}}
]
}
},
"aggs": {
"failed_logins_by_ip": {
"terms": {"field": "source_ip", "size": 100},
"aggs": {
"failure_count": {"value_count": {"field": "event_id"}}
}
}
}
}
Các trường hợp sử dụng:
- Phát hiện đe dọa: Nhận diện các xâm nhập bảo mật
- Giám sát tuân thủ: Phân tích theo dõi bản ghi
- Đáp ứng sự cố: Khả năng điều tra nhanh chóng
5.7. Học máy và Ứng dụng AI
Tìm kiếm vector cho RAG (Retrieval-Augmented Generation):
{
"query": {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, 'content_vector') + 1.0",
"params": {
"query_vector": [0.1, 0.2, 0.3, ...]
}
}
}
}
}
Các trường hợp sử dụng:
- Tìm kiếm theo nghĩa: Tìm kiếm dựa trên nghĩa, không chỉ là từ khóa
- Hệ thống đề xuất: Đề xuất sản phẩm/nội dung
- Cơ sở tri thức: Hệ thống Q&A AI-powered
6. Ưu điểm và nhược điểm của Elasticsearch
6.1. Ưu điểm nổi bật
Hiệu suất tìm kiếm vượt trội:
- Tốc độ tìm kiếm dưới mili giây cho hàng triệu tài liệu
- Xử lý song song trên nhiều shard
- Cơ chế cache tiến tiến
Khả năng mở rộng linh hoạt:
- Mở rộng theo chiều ngang bằng cách thêm node
- Tự động cân bằng shard
- Mở rộng không có thời gian ngừng
Tính năng phong phú:
- Tìm kiếm toàn văn với tính năng khớp mờ
- Tổng hợp mạnh mẽ cho phân tích
- Khả năng tìm kiếm địa lý
- Tích hợp học máy
Thân thiện với lập trình viên:
- RESTful API với JSON
- Ngôn ngữ truy vấn DSL phong phú
- Tài liệu tuyệt vời
- Cộng đồng lớn hỗ trợ
Hệ sinh thái mạnh mẽ:
- Kibana cho trực quan hóa
- Logstash cho xử lý dữ liệu
- Beats cho thu thập dữ liệu
- Hàng trăm plugin
6.2. Nhược điểm và thách thức
Không phải cơ sở dữ liệu OLTP:
- Không hỗ trợ giao dịch ACID
- Tính nhất quán cuối cùng
- Không phù hợp làm kho dữ liệu chính
Độ phức tạp vận hành:
- Yêu cầu chuyên môn để tối ưu hóa
- Quản lý cluster phức tạp
- Thách thức về điều chỉnh bộ nhớ
- Độ phức tạp sao lưu và khôi phục
Cần nhiều tài nguyên:
- Yêu cầu RAM cao
- Các thao tác tốn CPU
- Chi phí lưu trữ cao (inverted index)
Vấn đề về tính nhất quán dữ liệu:
- Gần thời gian thực, không phải thời gian thực
- Có thể mất dữ liệu khi lỗi
- Thách thức trong đồng bộ hóa dữ liệu
Đường cong học tập:
- Query DSL phức tạp
- Điều chỉnh hiệu suất yêu cầu kinh nghiệm
- Gỡ lỗi khó khăn
6.3. Khi nào nên sử dụng Elasticsearch
Phù hợp khi:
- Cần tìm kiếm phức tạp trên tập dữ liệu lớn
- Hiệu suất là yêu cầu quan trọng
- Cần phân tích và bảng điều khiển thời gian thực
- Có nhóm có kinh nghiệm về công cụ tìm kiếm
- Dữ liệu chủ yếu để đọc
Không phù hợp khi:
- Cần giao dịch ACID
- Tập dữ liệu nhỏ (dưới 1M tài liệu)
- Tài nguyên hạn chế (bộ nhớ, chuyên môn)
- Tìm kiếm từ khóa đơn giản đã đủ
- Cập nhật/xóa thường xuyên
7. Hướng dẫn cài đặt Elasticsearch với Docker
7.1. Chuẩn bị môi trường
Trước khi bắt đầu, đảm bảo hệ thống của bạn có:
- Docker và Docker Compose
- Tối thiểu 4GB RAM sẵn có
- Ít nhất 10GB không gian đĩa
7.2. Cài đặt một node cho phát triển
Tạo file docker-compose.yml:
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ports:
- "9200:9200"
- "9300:9300"
volumes:
- elasticsearch-data:/usr/share/elasticsearch/data
networks:
- elastic
kibana:
image: docker.elastic.co/kibana/kibana:8.11.0
container_name: kibana
ports:
- "5601:5601"
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
networks:
- elastic
volumes:
elasticsearch-data:
networks:
elastic:
driver: bridge
Khởi chạy:
docker-compose up -d
7.3. Kiểm tra cài đặt
Kiểm tra Elasticsearch:
curl -X GET "localhost:9200/_cluster/health?pretty"
Truy cập Kibana: http://localhost:5601
7.4. Cài đặt cluster nhiều node
Cho production, cần setup multi-node cluster:
version: '3.8'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.0
container_name: es01
environment:
- node.name=es01
- cluster.name=docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
ports:
- "9200:9200"
volumes:
- es01-data:/usr/share/elasticsearch/data
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.0
container_name: es02
environment:
- node.name=es02
- cluster.name=docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
volumes:
- es02-data:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.0
container_name: es03
environment:
- node.name=es03
- cluster.name=docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
volumes:
- es03-data:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
es01-data:
es02-data:
es03-data:
networks:
elastic:
driver: bridge
7.5. Ví dụ sử dụng cơ bản
Tạo index và mapping:
curl -X PUT "localhost:9200/products" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "standard"
},
"price": {
"type": "integer"
},
"category": {
"type": "keyword"
},
"description": {
"type": "text"
},
"created_at": {
"type": "date"
}
}
}
}'
Lập chỉ mục tài liệu:
curl -X POST "localhost:9200/products/_doc/1" -H 'Content-Type: application/json' -d'
{
"name": "iPhone 15 Pro Max",
"price": 29990000,
"category": "smartphone",
"description": "Flagship smartphone từ Apple với chip A17 Pro",
"created_at": "2024-01-15"
}'
Tìm kiếm:
curl -X GET "localhost:9200/products/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"multi_match": {
"query": "iPhone",
"fields": ["name^2", "description"]
}
}
}'
8. Best Practices và Production Considerations
8.1. Performance Optimization
Thiết kế chỉ mục:
- Sử dụng số lượng shard phù hợp (1-5 cho hầu hết trường hợp)
- Tránh chia shard quá nhiều (nhiều shard nhỏ chậm hơn ít shard lớn)
- Lập kế hoạch cho tăng trưởng nhưng không cung cấp quá mức
Mapping Optimization:
- Disable
_allfield nếu không cần - Sử dụng
keywordcho exact matching - Set
index: falsecho fields không cần search
Tối ưu hóa truy vấn:
- Sử dụng bộ lọc thay vì truy vấn khi có thể
- Tránh phân trang sâu (sử dụng search_after)
- Cache các truy vấn thường xuyên
8.2. Giám sát và cảnh báo
Chỉ số quan trọng:
- Trạng thái sức khỏe cluster
- Tỷ lệ lập chỉ mục và tìm kiếm
- Sử dụng CPU và bộ nhớ của node
- Sử dụng không gian đĩa
- Độ trễ truy vấn
Công cụ:
- Elastic Stack Monitoring
- Prometheus + Grafana
- Kiểm tra sức khỏe tùy chỉnh
8.3. Sao lưu và khôi phục
Chiến lược ảnh chụp:
- Ảnh chụp hàng ngày đến kho lưu trữ từ xa
- Kiểm tra quy trình khôi phục thường xuyên
- Giám sát thành công/thất bại ảnh chụp
Quản lý vòng đời chỉ mục:
- Tự động hóa việc chuyển đổi chỉ mục
- Xóa chỉ mục cũ tự động
- Kiến trúc nóng-ấm-lạnh cho tập dữ liệu lớn
8.4. Security Considerations
Xác thực và phân quyền:
- Kích hoạt bảo mật X-Pack
- Sử dụng kiểm soát truy cập dựa trên vai trò
- Quản lý khóa API
Bảo mật mạng:
- Mã hóa TLS
- Lọc IP
- VPN hoặc mạng riêng
9. Tương lai của Elasticsearch và công nghệ tìm kiếm
9.1. AI và Machine Learning Integration
Tìm kiếm Vector: Elasticsearch đang tích hợp mạnh mẽ tìm kiếm vector để hỗ trợ các ứng dụng AI:
- Tìm kiếm ngữ nghĩa dựa trên embeddings
- Ứng dụng RAG (Retrieval-Augmented Generation)
- Tìm kiếm đa phương thức (văn bản, hình ảnh, âm thanh)
Xử lý ngôn ngữ tự nhiên: Tích hợp với các mô hình ML để:
- Hiểu truy vấn tốt hơn
- Mở rộng truy vấn tự động
- Nhận dạng ý định
9.2. Phát triển phân tích thời gian thực
Phân tích dòng dữ liệu: Hỗ trợ tốt hơn cho xử lý dữ liệu thời gian thực:
- Tích hợp với Kafka, Kinesis
- Xử lý sự kiện phức tạp
- Tổng hợp thời gian thực
Điện toán biên: Các phiên bản Elasticsearch nhẹ cho thiết bị biên.
9.3. Cloud-Native Development
Bản địa Kubernetes: Hỗ trợ tốt hơn cho triển khai containerized:
- Elastic Cloud on Kubernetes (ECK)
- Khả năng tự động mở rộng
- Chiến lược đa cloud
Tìm kiếm Serverless: Elastic đang phát triển các dịch vụ serverless để giảm chi phí vận hành.
Kết luận
Elasticsearch đã chứng tỏ mình là một trong những công cụ tìm kiếm mạnh mẽ và linh hoạt nhất hiện nay. Từ việc tìm kiếm sản phẩm trong thương mại điện tử đến phân tích log phức tạp, từ giám sát hệ thống đến xây dựng các ứng dụng AI hiện đại, Elasticsearch cung cấp nền tảng vững chắc cho hầu hết mọi nhu cầu về tìm kiếm và phân tích.
Tuy nhiên, sức mạnh đi kèm với trách nhiệm. Việc triển khai và vận hành Elasticsearch hiệu quả đòi hỏi hiểu biết sâu sắc về kiến trúc phân tán, điều chỉnh hiệu suất và thực hành vận hành tốt nhất. Đầu tư thời gian học hỏi và thực hành sẽ mang lại những lợi ích to lớn cho hệ thống của bạn.
Với sự phát triển không ngừng của công nghệ AI và dữ liệu lớn, Elasticsearch tiếp tục tiến hóa để đáp ứng những thách thức mới. Việc nắm vững Elasticsearch ngay hôm nay sẽ đặt nền móng vững chắc cho việc xây dựng các ứng dụng tìm kiếm và phân tích thế hệ tiếp theo.
Xem nhiều hơn bài viết của tôi tại đây nhé: codeeasy.blog
Tags: #Elasticsearch #Search-Engine #Backend #Analytics #Performance